- Slim-Llama reduces energy needs through binary/ternary quantization
- Achieves a 4.59-fold increase in efficiency and consumes between 4.69 and 82.07 mW at scale
- Supports 3B parameter models with 489 ms latency, enabling efficiency
Traditional large language models (LLM) often suffer from excessive power demands due to frequent access to external memory; However, researchers at the Korea Advanced Institute of Science and Technology (KAIST) have now developed Slim-Llama, an ASIC designed to address this problem through intelligent quantization and data management.
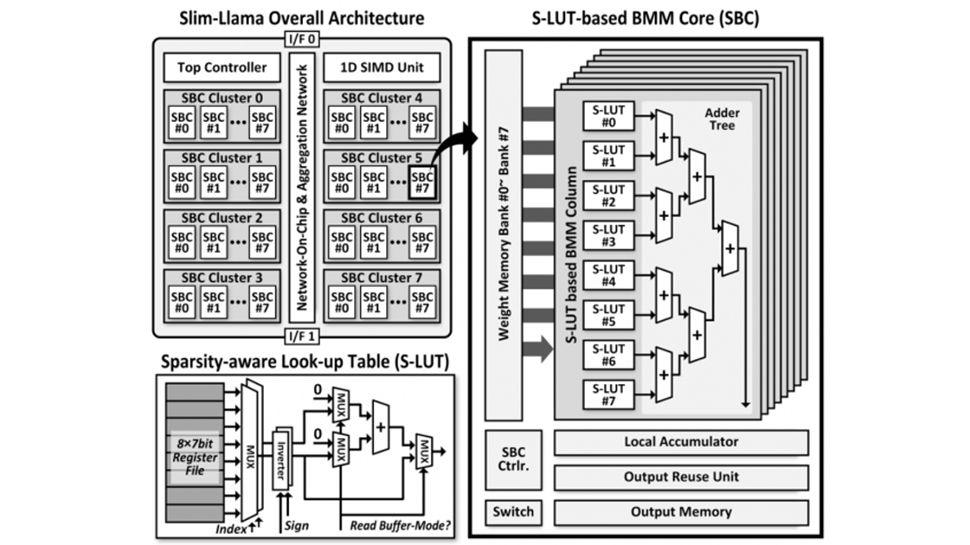
Slim-Llama employs binary/ternary quantization that reduces the precision of model weights to just 1 or 2 bits, significantly reducing computational and memory requirements.
To further improve efficiency, it integrates a sparsity-aware lookup table, which improves handling of sparse data and reduces unnecessary calculations. The design also incorporates a result reuse and index vector reordering scheme, minimizing redundant operations and improving data flow efficiency.
Reduced dependency on external memory.
According to the team, the technology demonstrates a 4.59x improvement in baseline energy efficiency compared to previous state-of-the-art solutions.
Slim-Llama achieves system power consumption as low as 4.69 mW at 25 MHz and scales to 82.07 mW at 200 MHz, maintaining impressive power efficiency even at higher frequencies. It is capable of delivering a maximum performance of up to 4.92 TOPS at 1.31 TOPS/W, further proving its efficiency.
The chip features a total die area of 20.25mm² and uses Samsung’s 28nm CMOS technology. With 500 KB of on-chip SRAM, Slim-Llama reduces reliance on external memory, significantly reducing energy costs associated with data movement. The system supports external bandwidth of 1.6GB/s at 200MHz, promising smooth data handling.
Slim-Llama supports models such as Llama 1bit and Llama 1.5bit, with up to 3 billion parameters, and KAIST says it offers benchmark performance that meets the demands of modern AI applications. With a latency of 489 ms for the 1-bit Llama model, Slim-Llama demonstrates efficiency and performance, making it the first ASIC to run billion-parameter models with such low power consumption.
Although it is early, this advancement in energy-efficient computing could pave the way for more sustainable and accessible AI hardware solutions, meeting the growing demand for efficient LLM implementation. The KAIST team will reveal more about Slim-Llama at the 2025 IEEE International Solid State Circuits Conference in San Francisco on Wednesday, February 19.


