Refresh
Outage reports for Slack, Zoom, Canva and
Good news – AWS now believes it has resolved this issue and services should return to normal very soon.
“We continue to see recovery in most of the affected AWS services,” it says on its status page. “We can confirm that global services and functions dependent on US-EAST-1 have also recovered. We continue to work toward a full resolution and will provide updates as we have more information to share.”
AWS has updated the severity status of the issues to “degraded” on their status page, which could again mean that a fix is imminent…
However, it’s worth noting that the US East Coast is about to wake up and come online – could this impact the recovery?
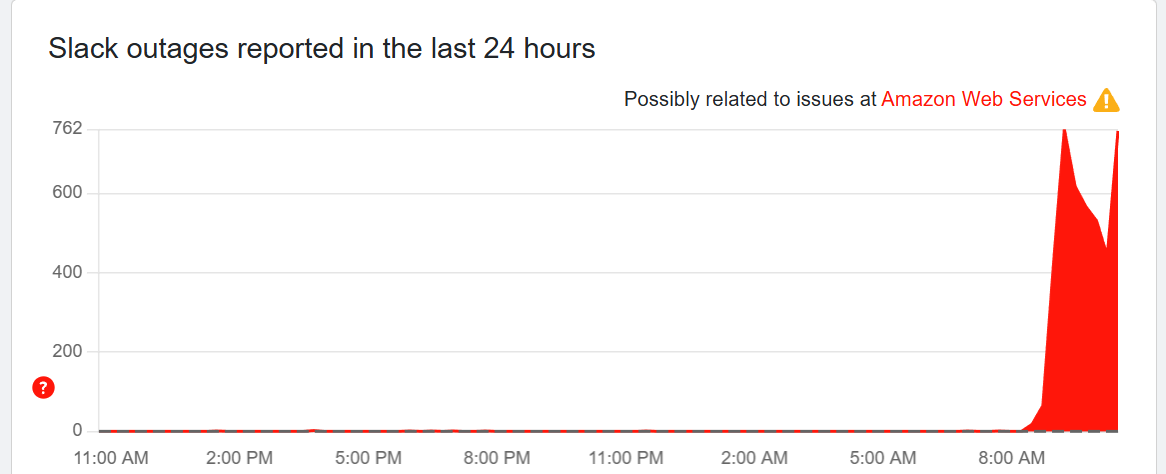
We’re not sure what exactly happened at Slack, but suddenly there was another major spike in outage reports.
The status page is still showing widespread issues, so it’s possible that there are simply more users logging in and seeing issues, or possibly something else?
Some expert insight from James Capell, our web hosting editor here at TechRadar Pro…
“The outage appears to be caused by a DNS resolution error for DynamoDB in the US-EAST-1 region. The DynamoDB database is used for many core AWS services, including IAM, which is used for permissions. The DNS error means that services that require it to work cannot access this database service. Since most AWS services depend on this service somewhere in the chain, we are seeing a lot of problems.”
Slack and Zoom are still reporting issues on their respective status pages, but both promised an update within the next 30 minutes.
As you can see in the screenshot below, DownDetector shows a rapid drop in reports…

And so, another AWS update, and it’s good news for all of us who want to continue working.
“October 20 at 2:27 am PDT We are seeing important signs of recovery. Most requests should now be successful. We are still working through a backlog of applications in the queue. “We will continue to provide additional information.”
A new update from AWS: “October 20 at 2:22 am PDT We have applied initial mitigations and are seeing early signs of recovery for some affected AWS services. During this time, requests may continue to fail while we work toward a full resolution. We recommend customers retry failed requests.”
“While requests are beginning to be successful, there may be additional latency and some services will have a backlog of work to resolve, which may take additional time to fully process. We will continue to provide updates as we have more information to share, or before 3:15 am.”
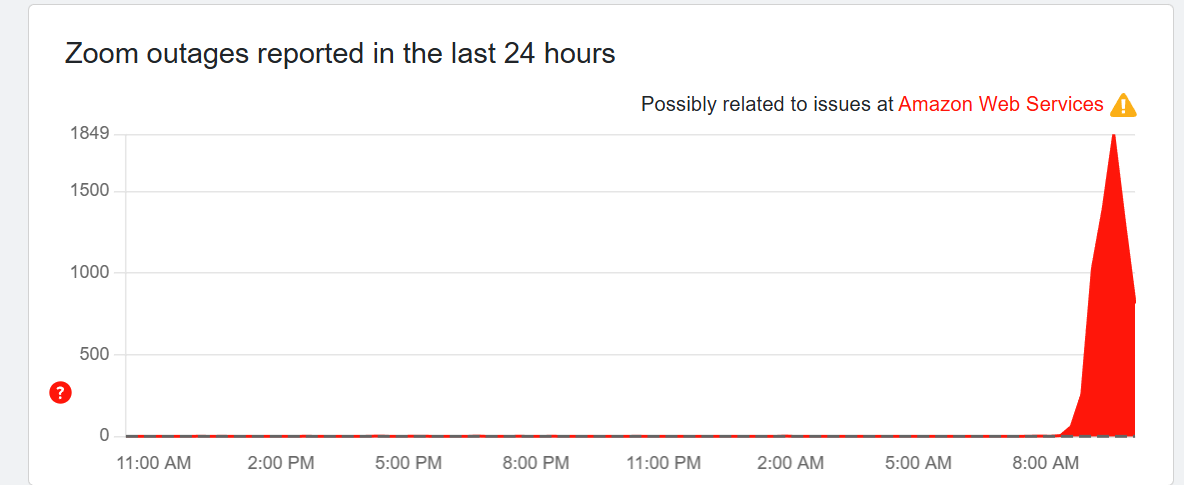
Outage reports are now falling from their peak on both Slack and Zoom, but it appears issues still persist across the board.
My Slack access just crashed completely, meaning I can’t communicate with my team or find out what they’re working on. Will no one think of the poor editors?
On Zoom, it appears that several parts of the platform have been affected and their status page is reporting several issues.
Zoom Chat, file transfers, Zoom Clips, and Zoom Contact Center are among the services showing “degraded performance.”
It’s not just Slack and Zoom: DownDetector also shows issues with other workplace tools, with Asana, Atlassian, Xero, and Jora affected (although reports appear to be declining now).
According to AWS’s own status page, the issue appears to arise from Amazon DynamoDB, which is the company’s managed NoSQL database platform, an important component for many customers and applications.
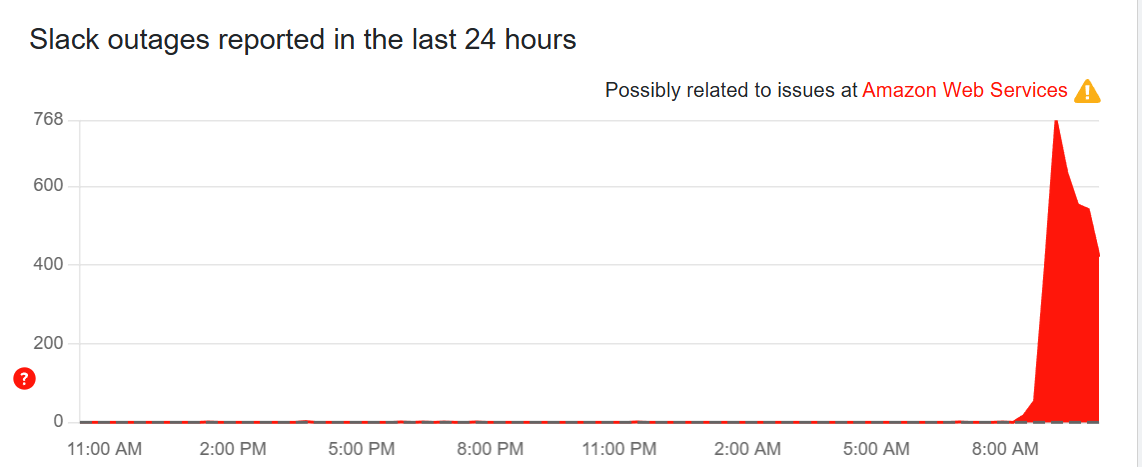
Slack is one of the most affected services, with problems across the board.
We’re Slack users here at TechRadar Pro and we’ve seen issues sending messages, links, and more, so you’re not alone.
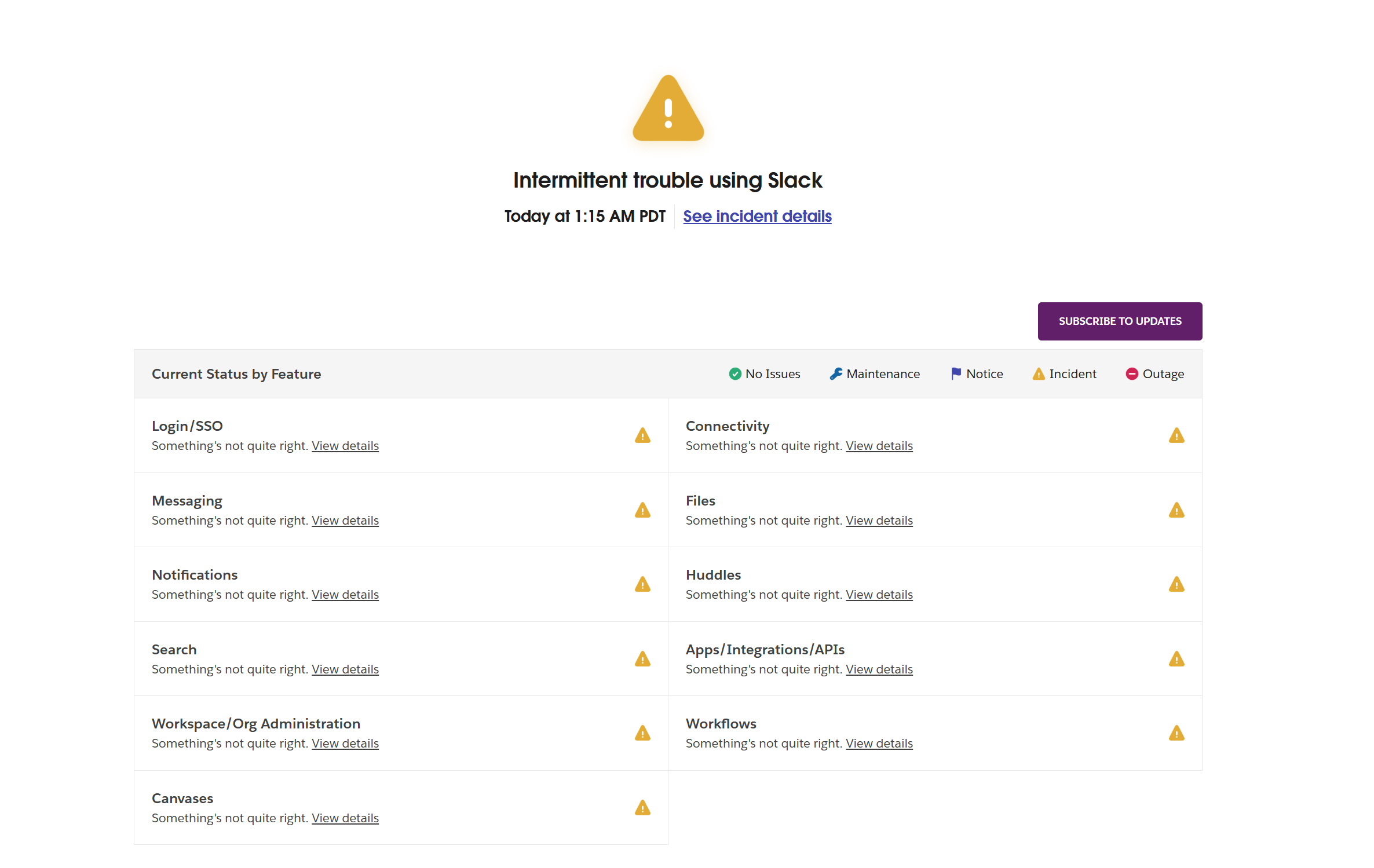
Since then, we’ve seen major outages across a number of consumer-focused services, along with work-focused tools: outage tracking site DownDetector shows the following…

Welcome to our live coverage of this major AWS outage.
The problems appeared to begin in the early hours of Monday morning, when the AWS US-EAST-1 region experienced problems, which have caused a ripple effect around the world.


